
Mike Mason's a little bewildered, but blogging anyway...
Mike is currently…
getting whipped at Halo

[ subversion book ]
obligatory book plug
[ syndicate ]
rss 2.0 feed for boy meets world
[ contact ]
drop me a line
[ about ]
this is mike mason's weblog
[ eskimoman.net ]
original web pages
Mon, 30 Apr 2007
Disabling Export Formats in Reporting Services
Reporting Services 2005 doesn’t allow you to selectively disable export formats for your reports. You can disable export formats for the whole server, but this is a bit useless in a shared environment. For my current client, we wanted to disable XML, Tiff and “web archive” export on all of our reports, but not affect any other reporting applications deployed on the server.
Our reports consist of custom parameter pages followed by a report view page onto which we’ve dropped a ReportViewer control. When the page loads, we programatically set the ReportViewer’s server URL, report path, and parameters. We’re doing this to ensure users are requesting reports for data that they’re allowed to see and not tricking us into revealing other users’ data.
Whilst there’s no official way to disable export formats on an individual report, a little bit of exploration using Reflector reveals that the ReportViewer contains a ServerReport that acts as a proxy between the control and the Reporting Services web service. The ServerReport allows you to list rendering extensions—these guys do the hard work of actually exporting in each format—but it doesn’t allow you to set the visibility of an extension. Reflection to the rescue!
The following code sample turns off XML, Tiff, and “web archive” export for a particular ReportViewer or ServerReport:
using System.Reflection;
using Microsoft.Reporting.WebForms;
using Microsoft.SqlServer.ReportingServices2005.Execution;
namespace MyProject
{
public class ServerReportDecorator
{
private readonly ServerReport serverReport;
public ServerReportDecorator(ReportViewer reportViewer)
{
this.serverReport = reportViewer.ServerReport;
}
public ServerReportDecorator(ServerReport serverReport)
{
this.serverReport = serverReport;
}
public void DisableUnwantedExportFormats()
{
foreach(RenderingExtension extension in serverReport.ListRenderingExtensions())
{
if(extension.Name == "XML" || extension.Name == "IMAGE"
|| extension.Name == "MHTML")
ReflectivelySetVisibilityFalse(extension);
}
}
private void ReflectivelySetVisibilityFalse(RenderingExtension extension)
{
FieldInfo info = extension.GetType().GetField("m_serverExtension",
BindingFlags.NonPublic
| BindingFlags.Instance);
if (info != null)
{
Extension rsExtension = info.GetValue(extension) as Extension;
if(rsExtension != null)
{
rsExtension.Visible = false;
}
}
}
}
}
I really hope Microsoft includes this functionality in the next release of Reporting Services. It would be really quite simple to include it in the graphical report designer and avoid this nasty reflection hack entirely. At the very least, the sealed RenderingExtension class could have a mutable “Visible” property, rather than the read-only property it has now.
Posted 23:11, 30 Apr 2007.
[ permalink ]
Wed, 21 Mar 2007
Card Infected
This whole Agile thing has messed me right up.

It’s not the most original idea—Joe Walnes had a card wall for renovating his house, where estimates were in money-costs rather than time—but it works well for me. I find myself getting a little stressed out when a personal project, even just “stuff I should do this week,” doesn’t have a card wall. Now that our wedding project has been successfully deployed I’ll be starting a card wall for happily ever after…
Posted 19:07, 21 Mar 2007.
[ permalink ]
Sat, 17 Mar 2007
CVS to Subversion Experience Report
My current client in Calgary recently switched from CVS to Subversion. Our main goal for switching was to fix performance problems with CVS, but we also hoped to get some benefit from the improved features within Subversion. The CVS repositories were on a reasonably beefy Sun box but we’d been seeing “waiting for lock” messages and frequent hanging of our CVS clients. The server didn’t look like it was under load and switching the repositories to their own mount point didn’t fix the problem. One of the teams also wanted to clean up their branching structure–after five years of CVS they were in a bit of a mess.
Our first conversion was straightforward. We wanted to convert a recent project from its existing home in a CVS module into Subversion. We used cvs2svn to do the conversion and ended up with around 6,000 revisions in Subversion. This represented about 18 months of effort from about a dozen developers, and the conversion took about 2 hours to run. The team’s developers had been briefed on the conversion and all checked in to CVS beforehand, then checked out from Subversion once we were ready. The entire team–including business users, analysts and testers–upgraded from TortoiseCVS to TortoiseSVN and pretty much carried straight on with their work.
We got the performance improvement we had hoped for, with a Subversion update taking around ten seconds compared to CVS’ one or two minutes. This is with the repository on the same Sun server, the only thing we needed to do was actually install the Subversion software.
The second conversion was more complicated. We wanted to take a 5GB CVS repository with five years of history and not only upgrade to Subversion, but sort out some branching problems. One of the branches within CVS had started out as a release branch but evolved into its own product maintained by a separate team. We also had a fairly complicated set of branches we didn’t want to include, tags that were no longer worthwhile, etc. We scripted the conversion by customizing the example cvs2svn-example.options file included with cvs2svn to get exactly what we wanted. The big “Eureka!” moment came when we realized that promoting the CVS branch to its own product was really easy once everything was in Subversion. cvs2svn converts branches and puts them into their own directory, but there’s nothing stopping us from moving a directory within Subversion. We simply copied the branch-that-is-a-product into a higher level, mirroring a regular project’s structure, then deleted its old location so developers wouldn’t get confused about which was the right one.
Converting the 5GB, five year old repository took around 16 hours over a weekend. Shuffling directories around once converted took only a few minutes, and we used the excellent TortoiseSVN Repository Browser so all our move operations ran directly against the repository and were lightning fast.
Posted 15:42, 17 Mar 2007.
[ permalink ]
Wed, 14 Jun 2006
Pragmatic Version Control Using Subversion, Take Two
I’m very pleased to announce that the second edition of Pragmatic Version Control Using Subversion has been published and is now shipping. As an author, it’s great to get an opportunity to update a published book, and for there to be enough interest that making an update is worthwhile.
Since the book first came out Subversion has come a long way, from version 1.0 to 1.3, adding new features and making improvements. I’ve also had a bunch of feedback on what people did and didn’t like in the book and this was a good opportunity to add some more content and address some of that feedback.
The book is still very much a guide for using version control in a pragmatic fashion, suitable for people who are new to version control as well as those with prior experience, but the new edition adds some more advanced stuff like programmatic access to a repository, path-based security, and file locking.
It’s my continued pleasure to work with Andy and Dave—if you’re an aspiring author with an idea for a book you should seriously drop them a line. The Pragmatic Programmers’ editorial expertise and publishing system is second-to-none, and best of all you won’t have to write your book using Word!
Posted 18:29, 14 Jun 2006.
[ permalink ]
Wed, 15 Feb 2006
Model, View, Presenter with ASP.NET 2.0
Most people are familiar with the Model, View, Controller pattern (MVC) for separating business logic and presentational logic within an application. MVC is implemented in a number of Java web frameworks, such as Struts and Spring. A more recent pattern–Model, View, Presenter–can be applied in contexts where there is no central “controller” for the application. One such framework is ASP.NET.
My team recently built an MVP-based application on ASP.NET 2.0 and had great success with highly testable presenters and a highly adaptable presentation layer. In fact, we chose to switch from creating custom web controls to using simple .aspx pages and didn’t have to change our presenters at all–it’s always nice to validate those previously abstrct design decisions!
The MVP pattern separates three elements. The model is one or more domain-specific objects representing the current state of the system, the information we’re trying to display, etc. The view is how we present that information to the user and handle input, usually a particular screen or web page. The presenter is the logic that ties together the model and the view, handles navigation, business logic requests, and model updates.
For MVP in ASP.NET 2.0, we use an .aspx page–or more precisely, the code behind partial class–as the view, custom domain objects as the model, and a Plain Old C# Object (can I steal the term POCO?) as the presenter. Let’s assume we’re creating a page to list customers in our application. Our ListCustomers.aspx page might look like this:
<asp:Content ContentPlaceHolderID="Main" Runat="Server">
<h1>Customer List</h1>
<asp:GridView ID="customerGridView" AutoGenerateColumns="false" runat="server" SkinID="CustomerGrid">
<Columns>
<asp:BoundField HeaderText="Customer" DataField="Name" />
</Columns>
</asp:GridView>
</asp:Content>
Nothing special here, we’ve just defined a GridView which will list the customers and display a title. What’s interesting is the code-behind:
public partial class ListCustomers : System.Web.UI.Page, IListCustomersView
{
protected void Page_Load(object sender, EventArgs e)
{
ICustomerService customerService = ServiceRegistry.GetService();
ListCustomersPresenter presenter = new ListCustomersPresenter(this, customerService);
presenter.PageLoading();
}
public List<Customer> Customers
{
set
{
customerGridView.DataSource = value;
customerGridView.DataBind();
}
}
}
The code-behind partial class implements IListCustomersView, which we’ll see in a moment. When the page is loaded we create a new ListCustomersPresenter, passing it the view (this) and anything else it requires (in this case, an ICustomerService). We then call the presenter’s PageLoading() method. What’s happening is that the code-behind is making no decisions about what to display on the page, it simply delegates to the presenter for any non-display-related business logic.
The IListCustomersView interface defines how the presenter can interact with the ASP page. There’s just one settable property, Customers:
public interface IListCustomersView
{
List<Customer> Customers { set; }
}
Looking back up at the code-behind, you can see that the implementation of the Customers property sets the grid view’s datasource to the list of customers and then calls DataBind() to populate the grid.
Let’s take a look at the final piece of the puzzle, the presenter:
public class ListCustomersPresenter
{
private readonly IListCustomersView view;
private readonly ICustomerService customerService;
public ListCustomersPresenter(IListCustomersView view, ICustomerService customerService)
{
this.view = view;
this.customerService = customerService;
}
public void PageLoad()
{
List<Customer> customers = customerService.GetAllCustomers();
view.Customers = customers;
}
}
When our presenter is constructed the two things it depends on, the view and the customer service, are passed to it (in this case, by the code-behind). This is known as constructor dependency injection. In the PageLoad() method the presenter simply accesses the customer service to load customers and sets this information on the view. This simple example can be extended to include input (the view can have read-only properties that correspond to text boxes, etc) and action (add a button to your web page and in the code-behind for its click call an action method on the presenter, like AddCustomerClicked()).
So why is this useful? Why not just have the code-behind access the CustomerService to load the customers? One of the main benefits is that the difficult business logic is captured in the presenter and can be more easily tested. Because we’re using dependency injection we can instantiate the presenter in an NUnit test, mock-out the view and service, and check the presenter does the right thing. The “load customers” example isn’t very hard but you can imagine logic that needed to take a set of user input and perform something more complex, such as placing an order. A second benefit is it’s very easy to see how the presenter can interact with the view–it can only use methods and properties on the IListCustomersView interface, which means it’s much easier for us to see the logical interface between the UI and the business layer. Finally, it’s possible to test drive your presenters and views, which tends to lead to simpler, more modular design for the system.
I’ve simplified some of the other stuff you’ll need to do in a real application. Screen flow and input validation are good examples. We solved the flow issue by having presenters able to return a “presenter result” object, indicating whether the ASP.NET framework should redirect to another page, stay on the current page, go to a login screen, etc. With input validation and error conditions, we add properties on the view so that the presenter can instruct the view to show a particular error message. You can still use an ASP.NET validator for client-side validation, but the presenter needs to be able to toggle it visible too.
We started our application using MVP, implementing the view using custom controls coded in C#. We did this mostly because we envisaged our application as a series of reusable controls, some of which (for example a Wiki control) should be embeddable in other applications. Ultimately we went a bit too far with this and coded some simple screenflow, which wasn’t really reusable, with the same C# controls. We found that layout and other tweaks became fairly onerous and decided to switch to implementing the view using traditional .aspx pages and code-behind. We found that our presenters required no changes at all to be able to accomodate the new view–excellent validation of the MVP design pattern.
Posted 22:01, 15 Feb 2006.
[ permalink ]
Wed, 19 Oct 2005
Splitting, Merging, and Organizing a Subversion Repository
When setting up Subversion within an organization, folks will often ask “How many repositories should I create?”—my advice is to just create one repository until you have a concrete need for more. I take this approach because it’s easy to split an existing repository into two. I also remind people it’s not the end of the world if they create multiple repositories and then they need to merge them, because Subversion has good support for splitting, merging, and reorganizing repositories. I’ve never really gone into any detail on how you actually do this stuff, but since I recently needed to merge two repositories I thought I’d share the technique I used.
Splitting a repository
First off make sure you tell everyone you’re going to split the repository. The ideal situation is where everyone can check in, go home for the night, leave you to organize stuff, and then come in the next day and start on something fresh. If people can’t commit all their changes you may need to help them relocate their working copy. Once everyone’s committed their changes, close down network access to your repository to be sure no-one’s committing further changes. This might be overkill depending on your situation, but it’s nice to be safe.
Next, back up your repository using svnadmin dump to create a dump file. A dump file is a portable representation of a Subversion repository and something you might be using for backups already. We’re going to load the dump file into a new repository, using svndumpfilter to select just the directories we wish to move to the new repository. A typical transcript might look like this:
[mgm@penguin temp]$ svnadmin dump /home/svnroot/log4rss > log4rss.dump
* Dumped revision 0.
* Dumped revision 1.
: : :
* Dumped revision 37.
* Dumped revision 38.
[mgm@penguin temp]$ mkdir tools-repos
[mgm@penguin temp]$ svnadmin create tools-repos
[mgm@penguin temp]$ cat log4rss.dump | svndumpfilter include log4rss/trunk/tools | svnadmin load tools-repos
Including prefixes:
'/log4rss/trunk/tools'
Revision 0 committed as 0.
Revision 1 committed as 1.
Revision 2 committed as 2.
: : :
<<< Started new transaction, based on original revision 38
------- Committed revision 38 >>>
In the above sample, I dumped the Log4rss repository into a file called log4rss.dump and created a new directory called tools-repos initialized with an empty repository. Then I piped my dump file through svndumpfilter and told it to include just the tools directory, and piped the result of the filter into svnadmin load into the new repository. I haven’t included it here, but I got a bunch of information about which items were included in the filter and which were dropped. Now the new tools-repos repository contains just the tools directory.
At this point, I can make the new repository available and tell developers where to find it. It’s probably also wise to delete the log4rss/trunk/tools directory from the original repository, just so people can’t accidentally use the old stuff. Subversion doesn’t have an obliterate command so the tools directory is still using space in the old repository—if this is an issue you’ll need to consider loading your dump file into a new repository using an “exclude” command to weed out the directory you no longer want.
Merging two repositories
My current project recently moved from Chicago to Calgary. For a while we had two teams running, using separate Subversion repositories. When everything moved to Calgary, we needed to merge the Chicago team’s code into our repository. We didn’t want to just import the files, we wanted to include historical information too.
We created a dump file of the Chicago team’s repository and loaded it straight into our repository using svnadmin load. This worked because the load command simply replays a series of commits, simulating what would have happened if the Chicago team had been working with us all along. The key thing to note here is that we had been using different directory paths in the two repositories, so their stuff didn’t conflict with ours. If they had used the same directory structure we would not have been able to simply load their changes into our repository. In that case, we would have had to work some magic with the dump file—it contains plain-text path definitions, so in a pinch we could have munged those path names so they didn’t conflict.
Organizing a repository
Once we’d loaded the Chicago code into our repository we used TortoiseSVN’s graphical repository browser to move the new stuff into our existing directory tree. Here’s a screenshot of the repo browser—it’s a great tool for this kind of thing and made reorganization very simple. We just used the “rename” command to move everything around in the repository, and once done we all checked out the newly organized directory tree and continued working.
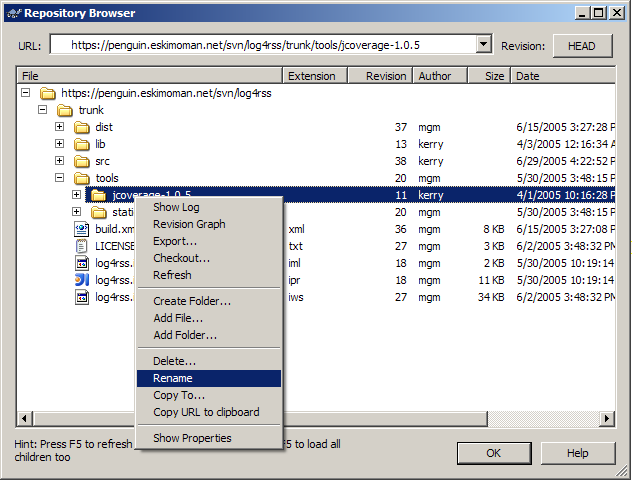
Posted 16:08, 19 Oct 2005.
[ permalink ]
Mon, 02 May 2005
Roots Conference in Norway
I’ve just spent a great couple of days attending the Roots Conference in Bergen, Norway. There were a bunch of very interesting people there and I had a fun time presenting. Norweigans seem to be very friendly and speak great English (lucky for me!).
My talk about Subversion Security includes some updated slides—if you have the proceedings CD you might want to grab the updated version. For the Test Driven Development session, we wrote a bunch of code which I thought people at the conference might like to see again, and you can grab that here including the slides.
Posted 22:19, 02 May 2005.
[ permalink ]
Wed, 30 Mar 2005
Shelving Subversion
My colleague Clinton Begin asked me whether Subversion supports shelving. This is something that the new Visual Studio may have as part of its “Team” features, and is basically a way for a developer to put aside a set of changes come back to them later. Storing shelved changes in your version control tool is pretty sensible—your repository is reliable, backed up, and not liable to disappear if someone pinches your laptop.
So can you do this kind of thing with Subversion? You betcha. Here’s roughly how it would work:
Whilst working on adding the new “frobscottle” feature Alice decides she’d like to shelve her current working copy changes. Her project, codenamed “xyzzy,” is checked out from
svn://svn.acme.com/xyzzy/trunk.Needing somewhere to store her changes, Alice branches the trunk to create
svn://svn.acme.com/xyzzy/shelves/alice/frobscottle.Alice uses the Subversion switch command to switch her working copy from the trunk to the new frobscottle branch. When switching, Subversion preserves any changes you’ve made to the working copy.
Alice checks in her working copy. The changes will be safely stored under the shelves directory.
Alice switches her working copy back to the trunk and works on something else. In future if she wants the shelved frobscottle changes she can merge from the branch to her trunk working copy, then commit the changes back into the main code line.
There are a few details you’ll need to get right—you may need to create the new branch from an older revision on the trunk rather than from the head—and it’s less pretty than a “shelve” button in a GUI, but it’ll work great and you’ll understand exactly where your changes actually are.
Posted 22:24, 30 Mar 2005.
[ permalink ]
Fri, 04 Mar 2005
Subversion FAQ
Pragmatic Version Control using Subversion launched Tuesday night in Calgary. I went down to a local bookstore and spent a few minutes talking about version control, Subversion, and what the book covered. The audience had a bunch of questions about Subversion and I took this as a really good sign — people are doing their own research and wanted to find out more.
Here’s a few of the questions people are asking about Subversion:
How does Subversion compare to other tools? Is there a feature matrix I can look at to decide what tool to use?
Subversion stacks up really well against CVS, fixing the bugs and fragility of CVS whilst keeping the proven development model. Subversion also adds features like change sets, atomic commit, decent networking performance, and a reliable back end. I’m wary of comparisons that read like a school book report, checking boxes if a tool has a particular feature. Those kinds of comparisons always tend to be biased by the person writing them — if you really want to know whether Subversion is right for you try it out on a small project. If things don’t work out you can try something else, if things do work out you’ll know more about the tool and will be better able to roll it out to larger projects.
I’ve heard that Subversion’s database can become corrupted. That doesn’t sound good!
Subversion 1.0 uses the Berkeley DB for storing your files, and this has been a source of some problems. BDB is very reliable when used properly, but unfortunately it’s quite finicky about permissions on its database files. If you set up a Subversion repository, usually on Unix, and have two different users access the repository, if their umask isn’t quite right they can grab control of those database files. This usually happens when you have more than one access mechanism, say svn+ssh as well as Apache. If BDB can’t write to its files it gets stuck, or “wedged.” People often confuse this with database corruption, which has only happened in a few cases and was traced to hardware problems.
Subversion 1.1 introduced the new “fsfs” back end which doesn’t use Berkeley DB and instead uses plain files on disk. This works much better for people using NFS, for example, and helps avoid some of the permissions problems. Most people can stick with BDB as long as they don’t try to mix network servers for Subversion.
I’ve heard Subversion supports “meta-data.” What’s that?
Using Subversion, you can attach named data to files and directories. Each name defines a property and properties can have textual or binary content. The nifty thing is that properties are version controlled in exactly the same way as files — Subversion tracks how their contents change over time, and can perform merges, deletes, and updates just like file contents. Subversion uses special properties to do stuff like ignoring certain files in a directory or setting the “execute bit” for a file.
Since properties are editable just like file contents, you could write a tool that used them in some special way. An example often given is a system that stores big graphic files — you could store a thumbnail inside a Subversion property for each file, then use that in your system.
Why would someone spend thousands on a commercial tool when they can get Subversion for free?
This is a good question, and one that I think a lot of people are beginning to ask. In the case of a version control tool, it may be that a company is happier using a product for which they can pay for support – if something goes wrong they can call someone and get it fixed. But open-source software is challenging the notion that you must pay for support. Subversion has an extremely active user community and you can often get a response in minutes, for free.
I like Perforce, and I actually think it’s better than Subversion in certain circumstances (usually when your branching has got out of control and you’re in a bit of a mess). But is Perforce several hundred dollars per head better than Subversion? I think probably not.
So what’s in Subversion that’s not in your new book?
This was actually the toughest question I faced during the book launch and I had to think for a long time before answering. I think the book covers 95% of Subversion’s features, and easily covers everything you’ll need when using Subversion on a typical project. I couldn’t cover all the advanced usages of Subversion, but I think having read the book you’ll be able to adapt what’s in there to cover any new situation you face.
The book sticks to the Subversion command line, and only covers GUI tools briefly, so you’ll need to experiment a little to figure out how Tortoise works, for example. I think it’s useful to understand what a GUI is doing “under the hood,” so I don’t see this as a serious omission. The book also doesn’t cover IDE integration because those tools are still evolving rapidly.
It looks like we’ll be doing another print run of the book, so be sure to get a copy of the first printing before we correct the typos!
Posted 01:30, 04 Mar 2005.
[ permalink ]
Tue, 01 Mar 2005
Finding Bugs Is Easy
…or so say the makers of FindBugs, an open-source bug detector for Java. When I’m asked to improve the code quality on a project often the first thing I do is to search for “obviously” bad code. By this I mean I look for stuff like String construction (you never need this in Java), incorrect use of static (makes testing hard, could be a sign people are using singletons), and a few others.
FindBugs takes this approach a step further using automated detectors that look for dodgy code. They work by scanning the compiled Java bytecode and looking for suspicious patterns. Running this against my current project found a multitude of sins, my favourite being the “looks right but is definitely buggy” covariant equals. Next best is the “database resource not closed” detector, and the “questionable reference comparison” detectory – try manually finding bugs caused by Integer object comparison using == instead of equals()…
FindBugs is has definitely found a place in my toolbox, and I’ll be running it regularly to avoid nasty suprises.
Posted 00:39, 01 Mar 2005.
[ permalink ]
| Mon | Tue | Wed | Thu | Fri | Sat | Sun |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
[ tim bacon ]
musings of an xp coach
[ ian bourke ]
enhancing core competencies since 1976
[ martin fowler ]
a cross between a blog and a wiki
[ alan francis ]
agile != good
[ paul hammant ]
part of the problem…
[ darren hobbs ]
the blog formerly known as pushing the envelope
[ mike roberts ]
on life and technology
[ chris stevenson ]
skizz-biz
[ joe walnes ]
joe's new jelly
[ rob baillie ]
oracle
Registered plugins: SmartyPants, antispam, bloglinks (v0.2), calendar (v0+6i), pluginfo (v1.0), and userstatus (v0.1)
This work is licensed under a
Creative Commons License.