Domain Driven Reporting
ThoughtWorks projects are built using best practices that include layered architectures, at the heart of which is often a domain model. The model contains concepts and business logic to support the application. The model is often persisted using an object relational mapping scheme with either custom code or a mapping tool such as Hibernate. Our domain model is used to drive screens and processes within the application. But when it comes time to writing those pesky reports that the business desperately needs, we tend to revert back to plain old SQL stored procedures. This article shows how we can leverage a .NET C# domain model to create traditional Reporting Services reports.
The Bad Old Days
Microsoft Reporting Services is a standard part of the .NET stack. When faced with a reporting requirement on a .NET project, we’d need to do a lot of explaining to choose a different reporting tool, and we’d be taking some chances. For this article we’ll assume the political or technical environment doesn’t allow us to choose another tool or to avoid reports entirely. It is usually still worth asking the business whether an interactive screen will serve their needs instead of a report—on a current project in Calgary the business champion understands that a screen is faster to develop and easier to test than a Reporting Services report. He will often choose a screen instead of a report where functionality such as PDF export or printability is not required.
The Reporting Services authoring tool is designed around SQL or stored procedure development. The default data source is an SQL data source, and the tool works well alongside a SQL editing environment where we can develop our queries. Reporting Services uses SQL based data sources for report parameters too. This leads many of us to conclude that the right way to use Reporting Services is to develop custom SQL for report parameters and data sets. SQL cannot leverage our domain model, so we end up repeating many business rules and concepts within our reporting SQL. Since SQL or even T-SQL is less expressive than C# code, and since most programmers are less adept at database programming, our reporting SQL gets unwieldy, complicated, and bug ridden. Maybe we add some views or functions to attempt to clarify things. Then we tune our SQL so the reports perform well. The result is often a really nasty section of our application that no-one wants to work on, and that can often contain bugs. Reports are usually important for running the business, so the numbers must be right.
Web Services to the Rescue!
A little-advertised feature within Reporting Services is its ability to consume Web Services as a data source. One reason this feature is poorly advertised might be Microsoft’s lack of expertise with applications that have a real domain model—most of their examples get as far as Data Access Objects but no further. Another reason is that the tool support for using web services isn’t as good as the support for SQL and stored procedures. It’s still quite usable, however.
The basic idea is to expose our existing domain model using web services, with methods specifically tailored to our reports. The SOAP response from a web service call is an XML document and is “flattened” into a dataset by reporting services. We can tune the way the flattening works to avoid extraneous elements (for example, we’re probably not interested in the SOAP envelope). Once we have the dataset we can write a report against it in the usual way.
A Web Services Driven Report
When creating a report you first need to define an XML data source. For the connection string enter the path to your web service.
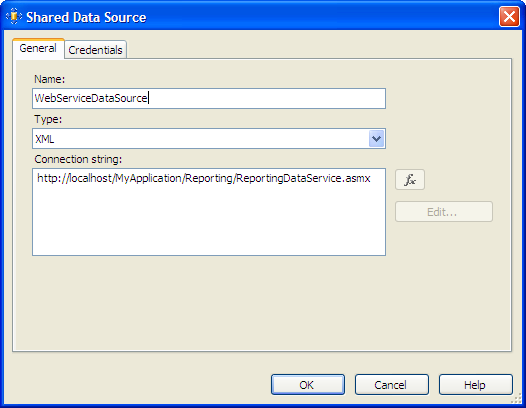
Now, add a new data set for the data source. The command type should be “text” and the query string an XML fragment including the method you wish to invoke on the web service. You should include parameters in your XML query for each parameter the web service method expects. In this example we have four parameters. We mapped the query parameters to report parameters using the “parameters” tab.
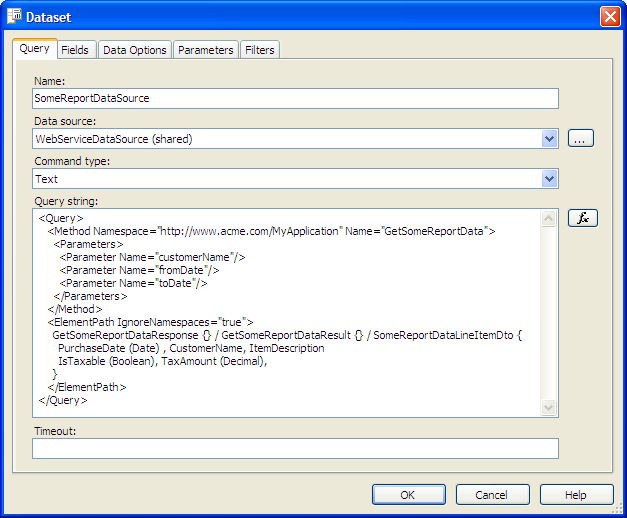
Beware that whilst you’re designing your report and setting up your data source, Reporting Services will often call your web service method using null for each parameter. Code your web service so that it checks for null and returns an empty response (empty list, zero response, etc) for one of these invalid calls, otherwise you’ll find the designer loses your query/parameter settings. This can be really annoying.
In our example we’re using ElementPath to collapse the web service XML response into a data set. The syntax is fairly arcane but you can try starting with a * as your element path which does a default conversion. You can read more about the syntax at Microsoft TechNet. We seem to need the Response {} and Result {} at the start of the path, even though those elements don’t actually occur in the web service SOAP response. In this example, we’re also forcing various fields to Reporting Services data types such as Date, Boolean and Decimal, rather than treating them as simple strings.
You should now be able to exercise your data source and see results come back. Now you can build the rest of your report in the designer as usual.
Performance Considerations
One common reason for using SQL or stored procedures for reporting is a worry about performance. Traditionally, a domain object approach is slower than using “raw” SQL. In fact this is always likely to be true—getting the database to do all the work will always be faster than loading objects into memory and processing them. But how fast do we really need a report to perform? And can we truly write database procedures that duplicate our business logic and get them to perform well?
Our experience in Calgary has shown that a report that took over two weeks to develop using stored procedures could be built in an afternoon using our domain model. Tuning the original report took considerable time, but we got to the point where we could generate an 850 page report in under 20 seconds. Initially the domain model version of the report took minutes to run, but with a small amount of tuning (only a few hours) we had it running in just ten seconds—twice as fast as the SQL based report. As an added benefit, the performance tuning we did on the domain model helps the entire application run faster. Tuning a domain model isn’t that hard; simply avoid loading too many objects into memory. Instead of loading 30,000 transaction entries and then processing them, we get the database to aggregate them by transaction type and date, something that we’d need to do in the domain model before displaying the results anyhow.
